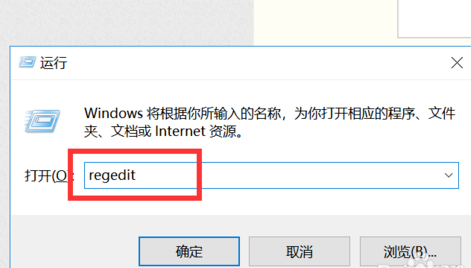
最近因为监控服务器时间莫名其妙的回到了几个月前,几十台监控服务器如果挨个去...
2019-12-08 3.48k
大家都知道,最近Teamviewer出了非常严重的漏洞,这给TeamViewer用户造成了巨大...
2020-11-15 3.02k
在用C#编写软件的过程中因为需要用到dataGridView这个控件,默认情况是这样显示...
2020-11-15 3.36k
js中this的四种调用模式主要分为方法调用模式、函数调用模式、构造器调用模式和...
2020-11-15 2.77k
相信很多人在使用帝国CMS的时候都遇到过同样的问题,用帝国默认的标签无法满足...
2019-12-08 2.09k